
Reintegrating streaming with php legacy service
A while back, I was tasked to look into the problem of disappearing events in a streaming pipeline. The stakeholders complained of the data/status not being updated.
Problem
The following diagram describes how the data (events) flows:
Architecture
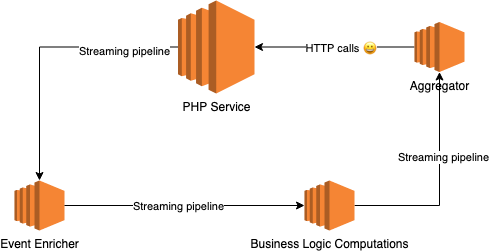
In the context of this post, two components are important here:
- Aggregator
- This is a service that consumes events concurrently from a stream and aggregates them into a single result event.
- PHP Service
- This is a big php service that consists of multiple web requests handler and cron jobs. Note that this service was not performing well. It performed badly under high load and was being replaced soon.
The communication between ‘Aggregator’ and ‘PHP Service’ happens synchronously by calling the http endpoint of the php service to ‘pass’ the event to it. If the call timeouts, we retry a couple of times (the max was 3).
The issue here is that the php service was not able to handle all requests and was timing out quite a lot. Despite increasing the number of retries - the issue wasn’t resolved. After reaching the limit, the event is not passed and next event will be attempted to be passed.
Solution
When calling the ‘php service’ for every event, we expect a reply instantly, which makes this communication style fragile when it fails, and puts an expectation for the php service to have high availablity which was not possible due to its bad performance.
Async communication is instead applied with help of a FIFO queue. That way, instead of expecting the php service to perform, we give it a chance to work on its own pace. Since our cloud provider did not provide the stream consumer api for PHP, I instead used the alternative option which we already use - queues.
Using partitioning, It is possible to order events in a distributed manner and also retry the failed events. This allows to unblock events that are not related to each other.

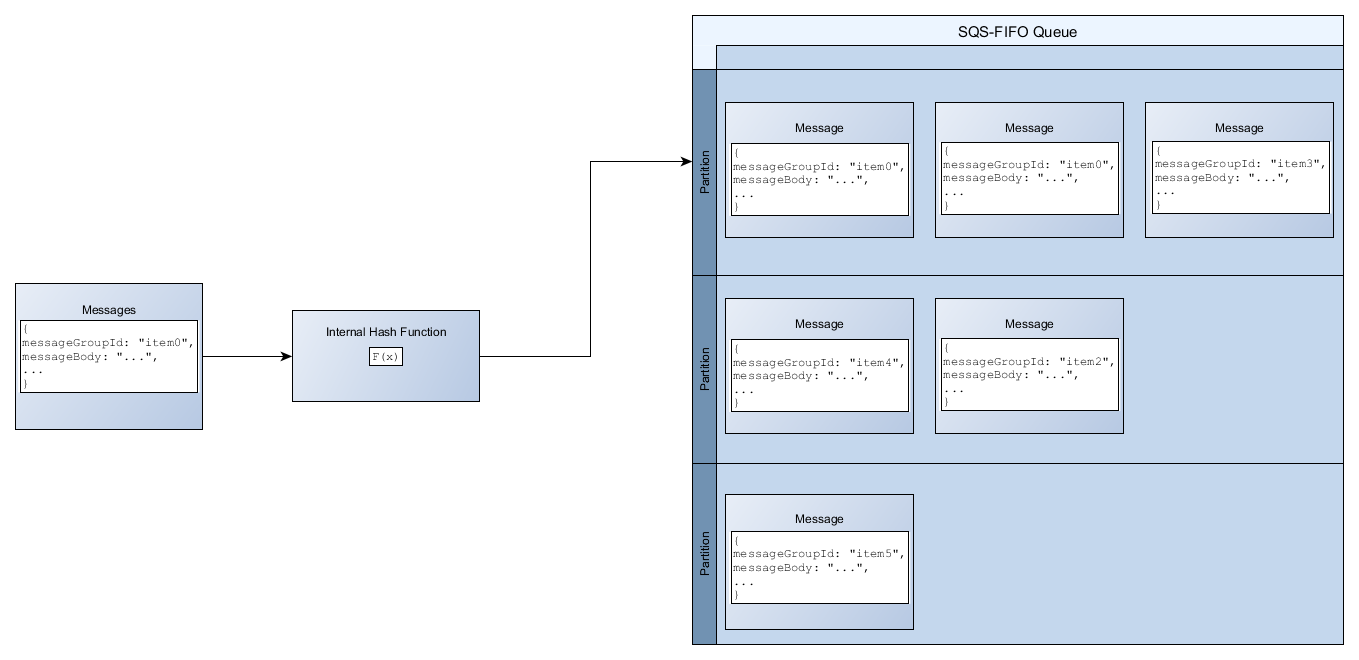 Above diagram source
Above diagram source
New Architecture Result
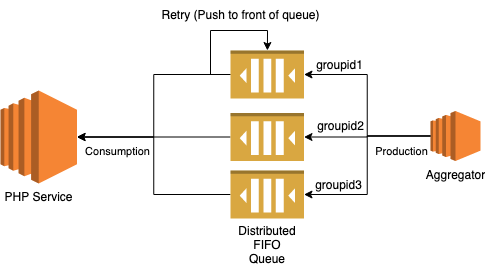
Also, DLQ was added to be able to debug unprocessed events easily.
So in summary, while php was a service that was near its End of Service, it was still crucial to keep the events being processed to not lose the product quality and revenue. The problem was solved with an existing tool that was already used, and identifying the root cause of the bottleneck.
Failures
While rolling out the above solution, I didn’t setup the queue correctly, which lead to a lot of events being not passed to downstream. Such change is better released gradually with feature flag and canary release to have minimum downtime in dire times.
Comments